You can download this .qmd file from here. Just hit the Download Raw File button.
Using rvest for web scraping
If you would like to assemble data from a website with no API, you can often acquire data using more brute force methods commonly called web scraping. Typically, this involves finding content inside HTML (Hypertext markup language) code used for creating webpages and web applications and the CSS (Cascading style sheets) language for customizing the appearance of webpages. We are used to reading data from .csv files…. but most websites have it stored in XML (like html, but for data). You can read more about it here if you’re interested: https://www.w3schools.com/xml/default.asp
XML has a sort of tree or graph-like structure… so we can identify information by which node it belongs to (html_nodes) and then convert the content into something we can use in R (html_text or html_table).
Here’s one quick example of web scraping. First check out the webpage https://www.cheese.com/by_type and then select Semi-Soft. We can drill into the html code for this webpage and find and store specific information (like cheese names)
session <-bow("https://www.cheese.com/by_type", force =TRUE)result <-scrape(session, query=list(t="semi-soft", per_page=100)) |>html_node("#main-body") |>html_nodes("h3") |>html_text()head(result)
#> [1] "3-Cheese Italian Blend" "Abbaye de Citeaux" #> [3] "Abbaye du Mont des Cats" "Adelost" #> [5] "ADL Brick Cheese" "Ailsa Craig"
Four steps to scraping data with functions in the rvest library:
robotstxt::paths_allowed() Check if the website allows scraping, and then make sure we scrape “politely”
read_html(). Input the URL containing the data and turn the html code into an XML file (another markup format that’s easier to work with).
html_nodes(). Extract specific nodes from the XML file by using the CSS path that leads to the content of interest. (use css=“table” for tables.)
html_text(). Extract content of interest from nodes. Might also use html_table() etc.
Data scraping ethics
Before scraping, we should always check first whether the website allows scraping. We should also consider if there’s any personal or confidential information, and we should be considerate to not overload the server we’re scraping from.
Chapter 24 in R4DS provides a nice overview of some of the important issues to consider. A couple of highlights:
be aware of terms of service, and, if available, the robots.txt file that some websites will publish to clarify what can and cannot be scraped and other constraints about scraping.
use the polite package to scrape public, non-personal, and factual data in a respectful manner
scrape with a good purpose and request only what you need; in particular, be extremely wary of personally identifiable information
See this article for more perspective on the ethics of data scraping.
When the data is already in table form:
In this example, we will scrape climate data from this website
The website already contains data in table form, so we use html_nodes(. , css = "table") and html_table()
# check that scraping is allowed (Step 0)robotstxt::paths_allowed("https://www.usclimatedata.com/climate/minneapolis/minnesota/united-states/usmn0503")
www.usclimatedata.com
[1] TRUE
# Step 1: read_html()mpls <-read_html("https://www.usclimatedata.com/climate/minneapolis/minnesota/united-states/usmn0503")# 2: html_nodes()tables <-html_nodes(mpls, css ="table") tables # have to guesstimate which table contains climate info
# 3: html_table()html_table(tables, header =TRUE, fill =TRUE) # find the right table
[[1]]
# A tibble: 6 × 7
`` JanJa FebFe MarMa AprAp MayMa JunJu
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Average high in ºF Av. high Hi 24 29 41 58 69 79
2 Average low in ºF Av. low Lo 8 13 24 37 49 59
3 Days with precipitation Days precip.… 8 7 11 9 11 13
4 Hours of sunshine Hours sun. Sun 140 166 200 231 272 302
5 Av. precipitation in inch Av. precip… 0.9 0.77 1.89 2.66 3.36 4.25
6 Av. snowfall in inch Snowfall Sn 12 8 10 3 0 0
[[2]]
# A tibble: 6 × 7
`` JulJu AugAu SepSe OctOc NovNo DecDe
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Average high in ºF Av. high Hi 83 80 72 58 41 27
2 Average low in ºF Av. low Lo 64 62 52 40 26 12
3 Days with precipitation Days precip.… 10 10 9 8 8 8
4 Hours of sunshine Hours sun. Sun 343 296 237 193 115 112
5 Av. precipitation in inch Av. precip… 4.04 4.3 3.08 2.43 1.77 1.16
6 Av. snowfall in inch Snowfall Sn 0 0 0 1 9 12
[[3]]
# A tibble: 31 × 7
Day HighºF LowºF `Prec/moinch` `Prec/yrinch` `Snow/moinch` `Snow/yrinch`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 Jan 23.8 8.3 0.04 0.04 0.39 1
2 2 Jan 23.7 8.2 0.08 0.08 0.71 1.8
3 3 Jan 23.6 8.1 0.12 0.12 1.1 2.8
4 4 Jan 23.5 7.9 0.12 0.12 1.5 3.8
5 5 Jan 23.5 7.8 0.16 0.16 1.81 4.6
6 6 Jan 23.4 7.7 0.2 0.2 2.2 5.6
7 7 Jan 23.4 7.6 0.24 0.24 2.6 6.6
8 8 Jan 23.3 7.5 0.28 0.28 3.11 7.9
9 9 Jan 23.3 7.4 0.28 0.28 3.5 8.9
10 10 Jan 23.3 7.3 0.31 0.31 3.9 9.9
# ℹ 21 more rows
[[4]]
# A tibble: 26 × 6
Day HighºF LowºF Precip.inch Snowinch `Snow d.inch`
<chr> <dbl> <dbl> <chr> <chr> <dbl>
1 01 Dec 32 19 0.07 1.61 7
2 02 Dec 27 12 0.00 0.00 6
3 03 Dec 37.9 19.9 0.00 0.00 6
4 04 Dec 39 24.1 0.00 0.00 6
5 05 Dec 37 21.9 0.00 0.00 5
6 06 Dec 32 17.1 0.00 0.00 5
7 07 Dec 42.1 21.9 0.00 0.00 5
8 08 Dec 41 30.9 0.00 0.00 5
9 09 Dec 34 -0.9 0.16 2.52 5
10 10 Dec 8.1 -4 T T 7
# ℹ 16 more rows
[[5]]
# A tibble: 9 × 4
`` `Dec 19` `` Normal
<chr> <chr> <lgl> <chr>
1 "Average high temperature Av. high temp." "29.9 ºF" NA "27 ºF"
2 "Average low temperature Av. low temp." "14.6 ºF" NA "12 ºF"
3 "Total precipitation Total precip." "0.39 inch" NA "1.16 inch"
4 "Total snowfall Total snowfall" "6.33 inch" NA "12 inch"
5 "" "" NA ""
6 "Highest max temperature Highest max temp." "44.1 ºF" NA "-"
7 "Lowest max temperature Lowest max temp." "8.1 ºF" NA "-"
8 "Highest min temperature Highest min temp." "32.0 ºF" NA "-"
9 "Lowest min temperature Lowest min temp." "-5.1 ºF" NA "-"
[[6]]
# A tibble: 10 × 3
`` `` ``
<chr> <chr> <lgl>
1 Country United States NA
2 State Minnesota NA
3 County Hennepin NA
4 City Minneapolis NA
5 Zip code 55401 NA
6 Longitude -93.27 dec. degr. NA
7 Latitude 44.98 dec. degr. NA
8 Altitude - Elevation 840ft NA
9 ICAO - NA
10 IATA - NA
[[7]]
# A tibble: 6 × 3
`` `` ``
<chr> <chr> <lgl>
1 Local Time 11:42 AM NA
2 Sunrise 07:06 AM NA
3 Sunset 05:47 PM NA
4 Day / Night Day NA
5 Timezone Chicago -6:00 NA
6 Timezone DB America/Chicago NA
[[8]]
# A tibble: 6 × 2
`` ``
<chr> <chr>
1 Annual high temperature 55ºF
2 Annual low temperature 37ºF
3 Days per year with precip. 112 days
4 Annual hours of sunshine 2607 hours
5 Average annual precip. 30.61 inch
6 Av. annual snowfall 55 inch
mpls_data1 <-html_table(tables, header =TRUE, fill =TRUE)[[1]] mpls_data1
# A tibble: 6 × 7
`` JanJa FebFe MarMa AprAp MayMa JunJu
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Average high in ºF Av. high Hi 24 29 41 58 69 79
2 Average low in ºF Av. low Lo 8 13 24 37 49 59
3 Days with precipitation Days precip.… 8 7 11 9 11 13
4 Hours of sunshine Hours sun. Sun 140 166 200 231 272 302
5 Av. precipitation in inch Av. precip… 0.9 0.77 1.89 2.66 3.36 4.25
6 Av. snowfall in inch Snowfall Sn 12 8 10 3 0 0
mpls_data2 <-html_table(tables, header =TRUE, fill =TRUE)[[2]] mpls_data2
# A tibble: 6 × 7
`` JulJu AugAu SepSe OctOc NovNo DecDe
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Average high in ºF Av. high Hi 83 80 72 58 41 27
2 Average low in ºF Av. low Lo 64 62 52 40 26 12
3 Days with precipitation Days precip.… 10 10 9 8 8 8
4 Hours of sunshine Hours sun. Sun 343 296 237 193 115 112
5 Av. precipitation in inch Av. precip… 4.04 4.3 3.08 2.43 1.77 1.16
6 Av. snowfall in inch Snowfall Sn 0 0 0 1 9 12
Now we wrap the 4 steps above into the bow and scrape functions from the polite package:
session <-bow("https://www.usclimatedata.com/climate/minneapolis/minnesota/united-states/usmn0503", force =TRUE)result <-scrape(session) |>html_nodes(css ="table") |>html_table(header =TRUE, fill =TRUE)mpls_data1 <- result[[1]]mpls_data2 <- result[[2]]
Even after finding the correct tables, there may still be a lot of work to make it tidy!!!
[Pause to Ponder:] What is each line of code doing below?
# A tibble: 12 × 7
month avg_high avg_low `Days with precipitation` `Hours of sunshine`
<chr> <dbl> <dbl> <dbl> <dbl>
1 Jan 24 8 8 140
2 Feb 29 13 7 166
3 Mar 41 24 11 200
4 Apr 58 37 9 231
5 May 69 49 11 272
6 Jun 79 59 13 302
7 Jul 83 64 10 343
8 Aug 80 62 10 296
9 Sep 72 52 9 237
10 Oct 58 40 8 193
11 Nov 41 26 8 115
12 Dec 27 12 8 112
# ℹ 2 more variables: `Av. precipitation in` <dbl>, `Av. snowfall in` <dbl>
# Probably want to rename the rest of the variables too!
Leaflet mapping example with data in table form
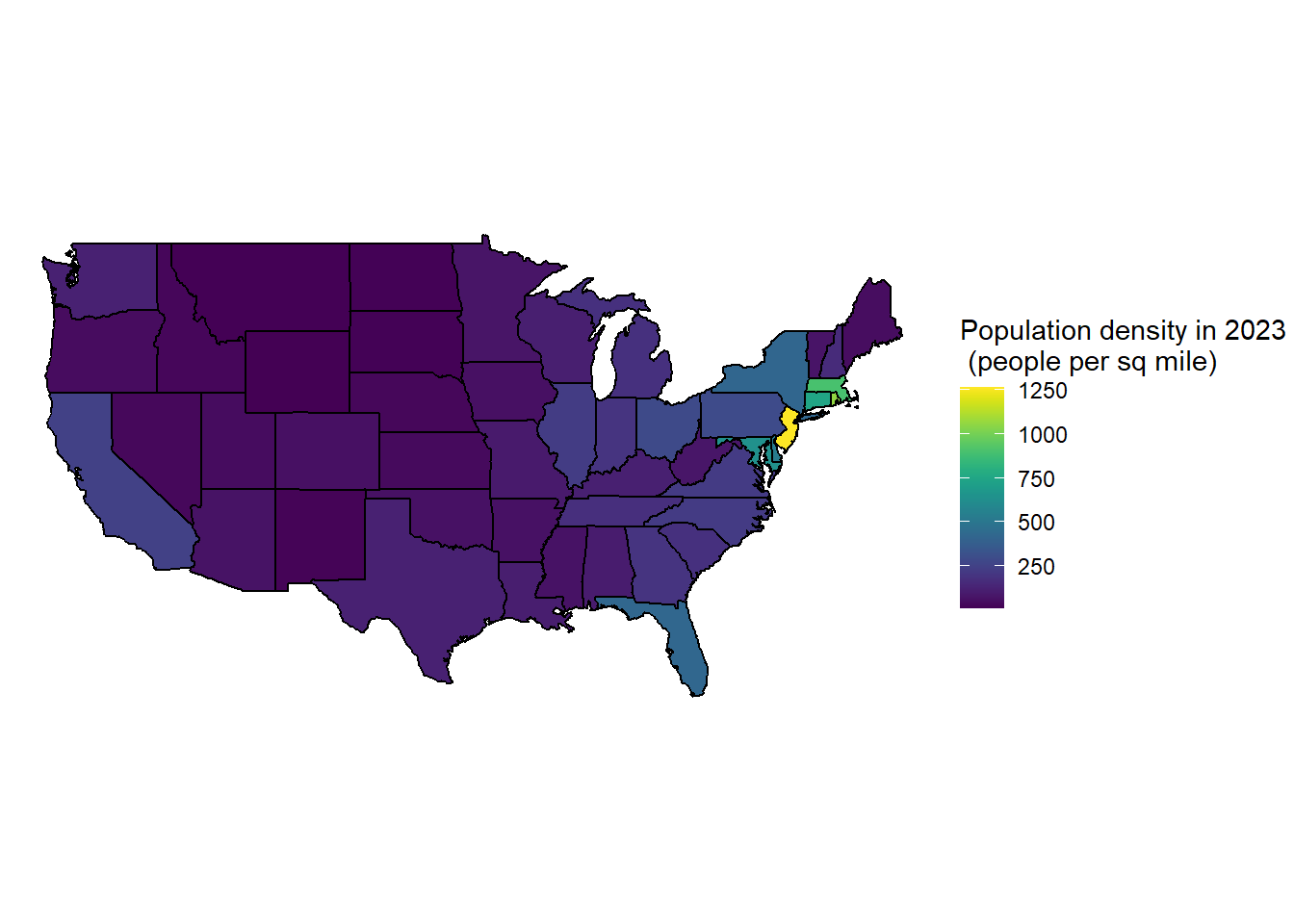
Let’s return to our example from 02_maps.qmd where we recreated an interactive choropleth map of population densities by US state. Recall how that plot was very suspicious? The population density data that came with the state geometries from our source seemed incorrect.
Let’s see if we can use our new web scraping skills to scrape the correct population density data and repeat that plot! Can we go out and find the real statewise population densities, create a tidy data frame, merge that with our state geometry shapefiles, and then regenerate our plot?
A quick wikipedia search yields this webpage with more reasonable population densities in a nice table format. Let’s see if we can grab this data using our 4 steps to rvesting data!
# check that scraping is allowed (Step 0)robotstxt::paths_allowed("https://en.wikipedia.org/wiki/List_of_states_and_territories_of_the_United_States_by_population_density")
en.wikipedia.org
[1] TRUE
# Step 1: read_html()pop_dens <-read_html("https://en.wikipedia.org/wiki/List_of_states_and_territories_of_the_United_States_by_population_density")# 2: html_nodes()tables <-html_nodes(pop_dens, css ="table") tables # have to guesstimate which table contains our desired info
# 3: html_table()html_table(tables, header =TRUE, fill =TRUE) # find the right table
[[1]]
# A tibble: 61 × 6
Location Density Density Population `Land area` `Land area`
<chr> <chr> <chr> <chr> <chr> <chr>
1 Location /mi2 /km2 Population mi2 km2
2 District of Columbia 11,131 4,297 678,972 61 158
3 New Jersey 1,263 488 9,290,841 7,354 19,047
4 Rhode Island 1,060 409 1,095,962 1,034 2,678
5 Puerto Rico 936 361 3,205,691 3,424 8,868
6 Massachusetts 898 347 7,001,399 7,800 20,202
7 Guam[4] 824 319 172,952 210 543
8 Connecticut 747 288 3,617,176 4,842 12,542
9 U.S. Virgin Islands[4] 737 284 98,750 134 348
10 Maryland 637 246 6,180,253 9,707 25,142
# ℹ 51 more rows
[[2]]
# A tibble: 11 × 2
.mw-parser-output .navbar{display:inline;font-size:8…¹ .mw-parser-output .n…²
<chr> <chr>
1 "List of states and territories of the United States" "List of states and t…
2 "Demographics" "Population\nAfrican …
3 "Economy" "Billionaires\nBudget…
4 "Environment" "Botanical gardens\nC…
5 "Geography" "Area\nBays\nBeaches\…
6 "Government" "Agriculture commissi…
7 "Health" "Changes in life expe…
8 "History" "Date of statehood\nN…
9 "Law" "Abortion\nAge of con…
10 "Miscellaneous" "Abbreviations\nAirpo…
11 "Category\n Commons\n Portals" "Category\n Commons\n…
# ℹ abbreviated names:
# ¹`.mw-parser-output .navbar{display:inline;font-size:88%;font-weight:normal}.mw-parser-output .navbar-collapse{float:left;text-align:left}.mw-parser-output .navbar-boxtext{word-spacing:0}.mw-parser-output .navbar ul{display:inline-block;white-space:nowrap;line-height:inherit}.mw-parser-output .navbar-brackets::before{margin-right:-0.125em;content:"[ "}.mw-parser-output .navbar-brackets::after{margin-left:-0.125em;content:" ]"}.mw-parser-output .navbar li{word-spacing:-0.125em}.mw-parser-output .navbar a>span,.mw-parser-output .navbar a>abbr{text-decoration:inherit}.mw-parser-output .navbar-mini abbr{font-variant:small-caps;border-bottom:none;text-decoration:none;cursor:inherit}.mw-parser-output .navbar-ct-full{font-size:114%;margin:0 7em}.mw-parser-output .navbar-ct-mini{font-size:114%;margin:0 4em}html.skin-theme-clientpref-night .mw-parser-output .navbar li a abbr{color:var(--color-base)!important}@media(prefers-color-scheme:dark){html.skin-theme-clientpref-os .mw-parser-output .navbar li a abbr{color:var(--color-base)!important}}@media print{.mw-parser-output .navbar{display:none!important}}vteUnited States state-related lists`,
# ²`.mw-parser-output .navbar{display:inline;font-size:88%;font-weight:normal}.mw-parser-output .navbar-collapse{float:left;text-align:left}.mw-parser-output .navbar-boxtext{word-spacing:0}.mw-parser-output .navbar ul{display:inline-block;white-space:nowrap;line-height:inherit}.mw-parser-output .navbar-brackets::before{margin-right:-0.125em;content:"[ "}.mw-parser-output .navbar-brackets::after{margin-left:-0.125em;content:" ]"}.mw-parser-output .navbar li{word-spacing:-0.125em}.mw-parser-output .navbar a>span,.mw-parser-output .navbar a>abbr{text-decoration:inherit}.mw-parser-output .navbar-mini abbr{font-variant:small-caps;border-bottom:none;text-decoration:none;cursor:inherit}.mw-parser-output .navbar-ct-full{font-size:114%;margin:0 7em}.mw-parser-output .navbar-ct-mini{font-size:114%;margin:0 4em}html.skin-theme-clientpref-night .mw-parser-output .navbar li a abbr{color:var(--color-base)!important}@media(prefers-color-scheme:dark){html.skin-theme-clientpref-os .mw-parser-output .navbar li a abbr{color:var(--color-base)!important}}@media print{.mw-parser-output .navbar{display:none!important}}vteUnited States state-related lists`
density_table <-html_table(tables, header =TRUE, fill =TRUE)[[1]] density_table
# A tibble: 61 × 6
Location Density Density Population `Land area` `Land area`
<chr> <chr> <chr> <chr> <chr> <chr>
1 Location /mi2 /km2 Population mi2 km2
2 District of Columbia 11,131 4,297 678,972 61 158
3 New Jersey 1,263 488 9,290,841 7,354 19,047
4 Rhode Island 1,060 409 1,095,962 1,034 2,678
5 Puerto Rico 936 361 3,205,691 3,424 8,868
6 Massachusetts 898 347 7,001,399 7,800 20,202
7 Guam[4] 824 319 172,952 210 543
8 Connecticut 747 288 3,617,176 4,842 12,542
9 U.S. Virgin Islands[4] 737 284 98,750 134 348
10 Maryland 637 246 6,180,253 9,707 25,142
# ℹ 51 more rows
# Perform Steps 0-3 using the polite packagesession <-bow("https://en.wikipedia.org/wiki/List_of_states_and_territories_of_the_United_States_by_population_density", force =TRUE)result <-scrape(session) |>html_nodes(css ="table") |>html_table(header =TRUE, fill =TRUE)density_table <- result[[1]]density_table
# A tibble: 61 × 6
Location Density Density Population `Land area` `Land area`
<chr> <chr> <chr> <chr> <chr> <chr>
1 Location /mi2 /km2 Population mi2 km2
2 District of Columbia 11,131 4,297 678,972 61 158
3 New Jersey 1,263 488 9,290,841 7,354 19,047
4 Rhode Island 1,060 409 1,095,962 1,034 2,678
5 Puerto Rico 936 361 3,205,691 3,424 8,868
6 Massachusetts 898 347 7,001,399 7,800 20,202
7 Guam[4] 824 319 172,952 210 543
8 Connecticut 747 288 3,617,176 4,842 12,542
9 U.S. Virgin Islands[4] 737 284 98,750 134 348
10 Maryland 637 246 6,180,253 9,707 25,142
# ℹ 51 more rows
Even after grabbing our table from wikipedia and setting it in a nice tibble format, there is still some cleaning to do before we can merge this with our state geometries:
# A tibble: 60 × 4
Density Population Land_area state_name
<dbl> <dbl> <dbl> <chr>
1 11131 678972 61 district of columbia
2 1263 9290841 7354 new jersey
3 1060 1095962 1034 rhode island
4 936 3205691 3424 puerto rico
5 898 7001399 7800 massachusetts
6 824 172952 210 guam[4]
7 747 3617176 4842 connecticut
8 737 98750 134 u.s. virgin islands[4]
9 637 6180253 9707 maryland
10 578 43915 76 american samoa[4]
# ℹ 50 more rows
As before, we get core geometry data to draw US states and then we’ll make sure we can merge our new density data into the core files.
# Get info to draw US states for geom_polygon (connect the lat-long points)states_polygon <-as_tibble(map_data("state")) |>select(region, group, order, lat, long)# See what the state (region) levels look like in states_polygonunique(states_polygon$region)
# Get info to draw US states for geom_sf and leaflet (simple features# object with multipolygon geometry column)states_sf <-read_sf("https://rstudio.github.io/leaflet/json/us-states.geojson") |>select(name, geometry)# See what the state (name) levels look like in states_sfunique(states_sf$name)
# Make sure all keys have the same format before joining: all lower casestates_sf <- states_sf |>mutate(name =str_to_lower(name))
# Now we can merge data sets together for the static and the interactive plots# Merge with states_polygon (static)density_polygon <- states_polygon |>left_join(density_data, by =c("region"="state_name"))density_polygon
# Looks like merge worked for 48 contiguous states plus DCdensity_polygon |>group_by(region) |>summarise(mean =mean(Density)) |>print(n =Inf)
# A tibble: 49 × 2
region mean
<chr> <dbl>
1 alabama 101
2 arizona 65
3 arkansas 59
4 california 250
5 colorado 57
6 connecticut 747
7 delaware 529
8 district of columbia 11131
9 florida 422
10 georgia 192
11 idaho 24
12 illinois 226
13 indiana 192
14 iowa 57
15 kansas 36
16 kentucky 115
17 louisiana 106
18 maine 45
19 maryland 637
20 massachusetts 898
21 michigan 178
22 minnesota 72
23 mississippi 63
24 missouri 90
25 montana 7.8
26 nebraska 26
27 nevada 29
28 new hampshire 157
29 new jersey 1263
30 new mexico 17
31 new york 415
32 north carolina 223
33 north dakota 11
34 ohio 288
35 oklahoma 59
36 oregon 44
37 pennsylvania 290
38 rhode island 1060
39 south carolina 179
40 south dakota 12
41 tennessee 173
42 texas 117
43 utah 42
44 vermont 70
45 virginia 221
46 washington 118
47 west virginia 74
48 wisconsin 109
49 wyoming 6
# Remove DC since such an outlierdensity_polygon <- density_polygon |>filter(region !="district of columbia")# Merge with states_sf (static or interactive)density_sf <- states_sf |>left_join(density_data, by =c("name"="state_name")) |>filter(!(name %in%c("alaska", "hawaii")))# Looks like merge worked for 48 contiguous states plus DC and PRclass(density_sf)
# Remove DC and PRdensity_sf <- density_sf |>filter(name !="district of columbia"& name !="puerto rico")
Numeric variable (static plot):
density_polygon |>ggplot(mapping =aes(x = long, y = lat, group = group)) +geom_polygon(aes(fill = Density), color ="black") +labs(fill ="Population density in 2023 \n (people per sq mile)") +coord_map() +theme_void() +scale_fill_viridis()
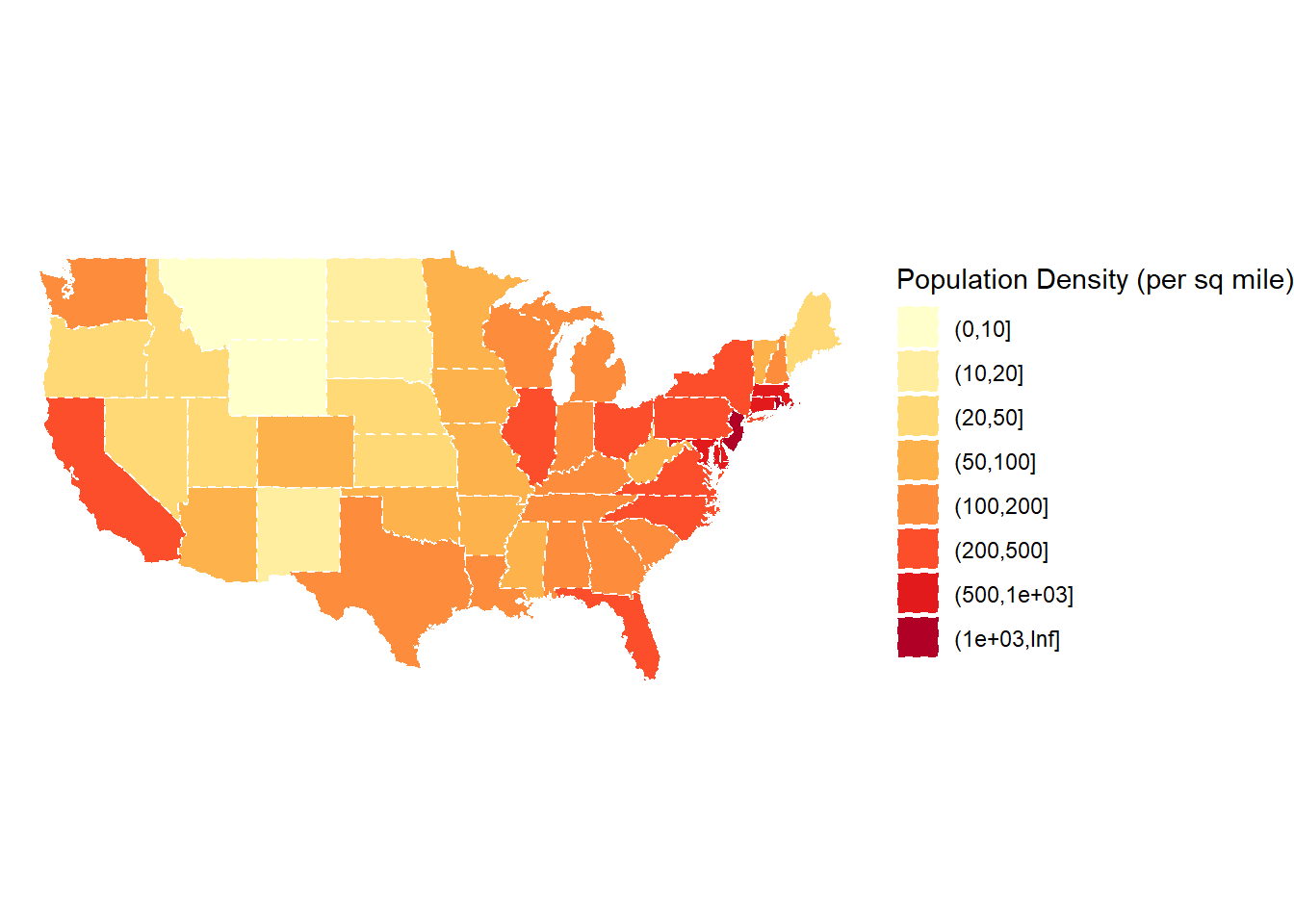
Remember that the original plot classified densities into our own pre-determined bins before plotting - this might look better!
density_polygon <- density_polygon |>mutate(Density_intervals =cut(Density, n =8,breaks =c(0, 10, 20, 50, 100, 200, 500, 1000, Inf)))density_polygon |>ggplot(mapping =aes(x = long, y = lat, group = group)) +geom_polygon(aes(fill = Density_intervals), color ="white",linetype =2) +labs(fill ="Population Density (per sq mile)") +coord_map() +theme_void() +scale_fill_brewer(palette ="YlOrRd")
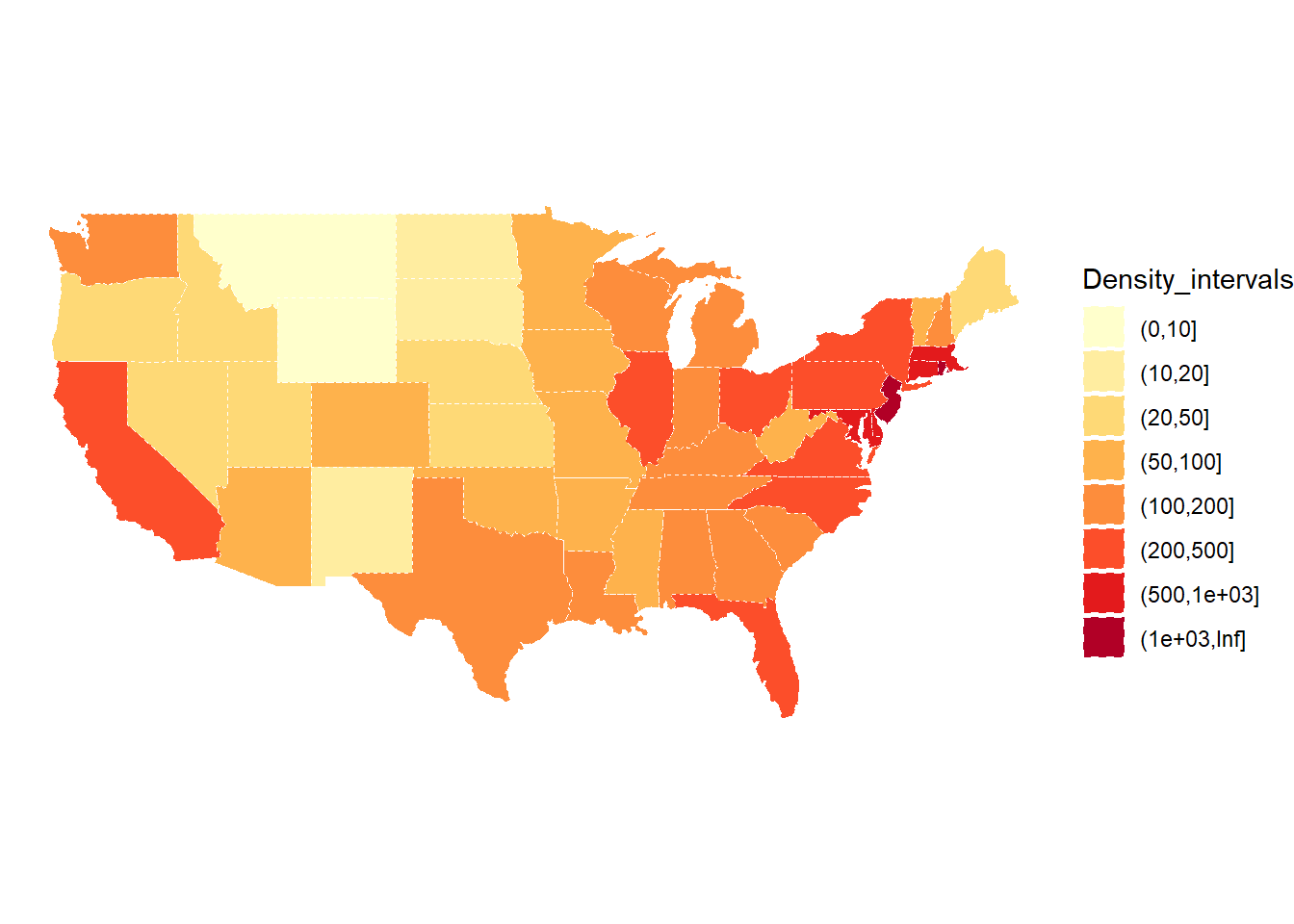
We could even create a static plot using geom_sf() using density_sf:
# should use addLegend() but not trivial without pre-set bins
Here’s an interactive plot with our own bins:
# Create our own category bins for population densities# and assign the yellow-orange-red color palettebins <-c(0, 10, 20, 50, 100, 200, 500, 1000, Inf)pal <-colorBin("YlOrRd", domain = density_sf$Density, bins = bins)# Create labels that pop up when we hover over a state. The labels must# be part of a list where each entry is tagged as HTML code.density_sf <- density_sf |>mutate(labels =str_c(name, ": ", Density, " people / sq mile"))labels <-lapply(density_sf$labels, HTML)# If want more HTML formatting, use these lines instead of those above:# states <- states |># mutate(labels = glue("<strong>{name}</strong><br/>{density} people / # mi<sup>2</sup>"))# labels <- lapply(states$labels, HTML)leaflet(density_sf) |>setView(-96, 37.8, 4) |>addTiles() |>addPolygons(fillColor =~pal(Density),weight =2,opacity =1,color ="white",dashArray ="3",fillOpacity =0.7,highlightOptions =highlightOptions(weight =5,color ="#666",dashArray ="",fillOpacity =0.7,bringToFront =TRUE),label = labels,labelOptions =labelOptions(style =list("font-weight"="normal", padding ="3px 8px"),textsize ="15px",direction ="auto")) |>addLegend(pal = pal, values =~Density, opacity =0.7, title =NULL,position ="bottomright")
On Your Own
Use the rvest package and html_table to read in the table of data found at the link here and create a scatterplot of land area versus the 2022 estimated population. I give you some starter code below; fill in the “???” and be sure you can explain what EVERY line of code does and why it’s necessary.
city_pop <-read_html("https://en.wikipedia.org/wiki/List_of_United_States_cities_by_population")pop <-html_nodes(???, ???)html_table(pop, header =TRUE, fill =TRUE) # find right tablepop2 <-html_table(pop, header =TRUE, fill =TRUE)[[???]]pop2# perform the steps above with the polite packagesession <-bow("https://en.wikipedia.org/wiki/List_of_United_States_cities_by_population", force =TRUE)result <-scrape(session) |>html_nodes(???) |>html_table(header =TRUE, fill =TRUE)pop2 <- result[[???]]pop2pop3 <-as_tibble(pop2[,c(1:6,8)]) |>slice(???) |>rename(`State`=`ST`,`Estimate2023`=`2023estimate`,`Census`=`2020census`,`Area`=`2020 land area`,`Density`=`2020 density`) |>mutate(Estimate2023 =parse_number(Estimate2023),Census =parse_number(Census),Change = ??? # get rid of % but preserve +/-,Area =parse_number(Area),Density =parse_number(Density)) |>mutate(City =str_replace(City, "\\[.*$", ""))pop3# pick out unusual pointsoutliers <- pop3 |>filter(Estimate2023 > ??? | Area > ???)# This will work if don't turn variables from chr to dbl, but in that # case notice how axes are just evenly spaced categorical variablesggplot(pop3, aes(x = ???, y = ???)) +geom_point() +geom_smooth() + ggrepel::geom_label_repel(data = ???, aes(label = ???))
We would like to create a tibble with 4 years of data (2001-2004) from the Minnesota Wild hockey team. Specifically, we are interested in the “Scoring Regular Season” table from this webpage and the similar webpages from 2002, 2003, and 2004. Your final tibble should have 6 columns: player, year, age, pos (position), gp (games played), and pts (points).
You should (a) write a function called hockey_stats with inputs for team and year to scrape data from the “scoring Regular Season” table, and (b) use iteration techniques to scrape and combine 4 years worth of data. Here are some functions you might consider:
row_to_names(row_number = 1) from the janitor package
clean_names() also from the janitor package
bow() and scrape() from the polite package
str_c() from the stringr package (for creating urls with user inputs)
map2() and list_rbind() for iterating and combining years
Try following these steps:
Be sure you can find and clean the correct table from the 2021 season.
Organize your rvest code from (1) into functions from the polite package.
Place the code from (2) into a function where the user can input a team and year. You would then adjust the url accordingly and produce a clean table for the user.
Use map2 and list_rbind to build one data set containing Minnesota Wild data from 2001-2004.